Loading... <div class="tip inlineBlock info"> 原文来自:[Hash tables in ClickHouse and C++ Zero-cost Abstractions](https://clickhouse.com/blog/hash-tables-in-clickhouse-and-zero-cost-abstractions) </div> # 概述 哈希表是数据结构中的女神。没有任何数据结构像哈希表一样如此容易在优化的过程中引入bug。这篇文章中,我们将讨论Clickhouse是如何使用哈希表的。我们将展示零开销抽象如何在现代C++中发挥作用,以及如何通过一些trick从一些基本代码的基础上构造各种数据结构。基于常见的构建模块,我们可以构建支持快速清除的哈希表、多种类型的LRU-cache、使用哈希的查找表以及字符串哈希表。我们还会展示如何在特定场景下确保最佳性能,以及如何避免在测试性能时犯错。这些都是我们ClickHouse最爱搞的底层优化! 首先,让我们讨论为什么需要哈希表、数据库中的哪些地方可以使用哈希表,以及如何使哈希表达到最佳性能。然后,我们会看看网上针对不同哈希表的benchmark,并解释如何正确实现它们。最后,我们将介绍我们的零开销C++框架,它支持了针对不同的使用场景生成理想的哈希表。 # Clickhouse中的应用 ClickHouse凭借其能够以闪电般的速度聚合海量数据而闻名。SQL中的聚合由 `GROUP BY`子句表示。包括ClickHouse在内的大多数数据库都使用某种把GROUP列作为Key来存储数据到哈希表中的哈希聚合算法来实现 `GROUP BY`。选择合适的哈希表对性能至关重要,这取决于GROUP列的数据类型(例如:定长整数?变长字符串?......)、基数、总数据量以及其他因素。ClickHouse对 `GROUP BY`子句进行了 40 多种不同的优化,每种优化都以不同的方式使用高度优化的哈希表,并利用强大的框架生成最合适的哈希表! 如果说我们只有一个哈希表,那就不对了。我们有很多哈希表,它们都是围绕灵活且强大的框架构建的。这些变种主要用于执行 `GROUP BY`和 `JOIN`操作。  哈希表是一种能够提供平均常数时间复杂度进行增、删、查操作的数据结构。 在 `GROUP BY`场景下,删的性能表现并不重要。  请看上图。大多数开发者都会从早期的CS课程中了解到哈希表的结构。我们用对于要插入的值计算hash函数结果,然后对数组长度取模得到它最终要插入的位置。 # 哈希表设计 哈希表是一种非常复杂的数据结构,需要在不同层次上做出许多设计决策。每个决策本身都会对哈希表产生重要影响,但多个设计决策共同作用的方式也会产生影响。设计阶段的失误会导致实现效率低下,明显降低性能。哈希表由哈希函数、碰撞解决方法、扩缩容策略以及不同的在内存中重排元素的可能方式组成。 ## 选择哈希函数 让我们从选择哈希函数开始。这是一个非常重要的设计决策,由于[潜在的选择](https://clickhouse.com/docs/en/sql-reference/functions/hash-functions)很多,而且似乎所有的选择都能产生同样好的随机值,因此很多人经常会犯错。我们将概述这一决策过程中存在的主要问题。 首先,对于整数类型,许多人通常会使用**恒等映射来作为哈希函数。这是不对的**,因为真实数据的分布并不相同,会出现大量碰撞。此外,有些哈希函数针对整数进行了优化,如果数据允许,可以使用它们而不是通用哈希函数。此外,除非您预计会受到攻击,否则不要使用各种加密哈希函数,因为这些函数的计算成本较高。例如,假设您使用的加密Sip哈希的吞吐量约为1GB/秒,而City哈希函数的吞吐量约为10GB/秒。选择加密Sip哈希意味着你的表的吞吐量将被限制在1GB/秒。 此外,不要使用FNV1a等传统哈希函数,因为它们速度过慢,而且与其他选择相比起来,FNV1a的分布更不均匀。GCC标准库中使用了这种特定的哈希函数,但它已被弃用。GitHub上的[SMHasher代码库](https://github.com/rurban/smhasher)包含各种哈希函数的测试,结果显示FNV1a未能通过任何严格的测试。 在ClickHouse中,我们默认使用的哈希函数虽然生成的分布相对较差,但对哈希表来说是很不错的。例如,**对于整数类型,我们使用CRC-32C**。这种哈希函数占用的CPU时间非常少,速度非常快,因为它可以通过[专用指令](https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html#ig_expand=1436&text=crc)来实现,只需2到3个时钟周期。对于字符串,我们使用基于CRC-32C的自定义哈希函数。如果你不想用这些,一些标准的哈希函数例如[Farm Hash](https://opensource.googleblog.com/2014/03/introducing-farmhash.html)也是可以考虑的。 ## 碰撞解决  让我们来谈谈碰撞解决的问题。根据[生日悖论](https://en.wikipedia.org/wiki/Birthday_problem),在任何哈希表中都会出现相同的key值落入到同一个单元的情况。假设我们插入了键K1,它进入了哈希表的第三个单元。现在我们要插入键K2,然后它经过计算也需要储存到如上图所示的同一个单元中。我们需要弄清楚接下来该如何处理它。有几种方法可以解决这种情况: 第一种是[拉链法](https://en.wikipedia.org/wiki/Hash_table#Separate_chaining),即表格单元格将使用列表或数组来容纳多个元素,我们将使用底层数据结构把下一个键放入同一个单元格。 第二种是[开放寻址法](https://en.wikipedia.org/wiki/Hash_table#Open_addressing)。在这种情况下,我们将冲突键按一定规则放在下一个单元中。[^open] 还有更复杂的方法,比如[布谷哈希](https://en.wikipedia.org/wiki/Cuckoo_hashing)[^cuckoo]或双路哈希[^two-way]。但是,这些方法都有一个问题:它们通常很难实现,需要对内存进行额外的读操作,通常在数据规模增大时速度会变慢。例如,在关键代码路径上进行大量操作,也会大大降低哈希表的查找速度。 ### 拉链法  让我们从最简单的方法开始谈——拉链法。这种方法利用一个列表来存放散列到同一单元格的元素。假设第一个键已经插入,那么第二个键就会被附加到第一个键下面的列表中。之后在查找过程中,主单元格及其子列表都会被检查是否存在对应的键。 这就是 `std::unordered_map`的哈希实现。为什么这种方法不好用?因为**它不是本地缓存,从而性能较差**。它的有效性在于,它在所有情况下都能正常工作,而且对所使用的哈希函数并不挑剔。即使负载率很高,它也能正常工作。但不幸的是,它将给分配器带来非常大的负载,因为在哈希表中的热路径中,即使调用任何函数,代价都会非常昂贵。因此,**所有现代哈希表都使用开放地址法**。 ### 开放寻址法  在本博客中,我将介绍三个值得关注的哈希表。其中两个是Google Flat Hash Map和Google Abseil Hash Map。Abseil是谷歌较新的框架之一,采用了略微不同的哈希方法。我们还将讨论ClickHouse中的哈希表。所有这些哈希表都使用开放寻址法。对于这种方法,当第二个键被哈希并分配到与第一个键相同的单元中时,我们会将其放入数组的下一个单元中——如上图所示。 “下一个单元”的选择取决于很多因素。我们可以使用[线性探查](https://en.wikipedia.org/wiki/Linear_probing),也就是说,我们选择下一个紧邻的单元。也可以使用[二次探查](https://en.wikipedia.org/wiki/Quadratic_probing),即我们以2的指数增长选择下一个单元,即1、2、4、8,以此类推。由于数据是通过处理器中的高速缓存行获取的,因此这提供了理想的cache命中率。这意味着**一次哈希键查找只相当于从内存中取一次数据**。这种方法的主要问题是,它需要一个适应数据的良好哈希函数。 假设我们选择了一个糟糕的哈希函数,我们很容易理解,在我们的数组中会出现“粘”在一起的簇。出现这种情况时,我们就会开始检查与我们正在查找的值无关的键。这种方法也不适合大型对象,因为它们会破坏所有缓存的本地性,使其主要优势变得多余。我们该如何解决这个问题呢?**我们将大型对象序列化,并将指向它们的指针存储在哈希表中**。 另一个非常重要的概念是[扩缩容](https://en.wikipedia.org/wiki/Hash_table#Dynamic_resizing)。首先,你需要决定调整大小的次数。有两种方法。第一种是保持表大小为2的幂次。这种方法的优点是,在查找表时,除法所花费的时间最少[^resize]。如果表存在于缓存中,执行时间仅为纳秒。如果不使用2的幂次,就会进行除法运算,这将耗费大量时间。然而如果表的大小始终是二的幂次,那么可以[用便宜的位移操作(>>)](https://github.com/ClickHouse/ClickHouse/blob/23.4/src/Common/HashTable/HashTable.h#L313)来代替昂贵的除法操作(%)。使用接近2的幂但也是质数的幂也有更多的理论依据,缺点是需要想办法避免除法。为此,我们可以使用某种常量开关或 `libdivide`[^libdivide]这样的库。 关于负载因子,除了Abseil哈希表之外,ClickHouse和所有Google的哈希表都使用0.5的负载因子。这是一个很好的数值,你可以在你的哈希表中使用。Abseil哈希表使用的负载率约为0.9。  最有趣的是单元在内存中的存放方式,这对保持哈希表的功能非常重要。 为什么我们需要一种特殊的方式来在内存中放置单元呢?一旦有人开始尝试编写开放寻址哈希表,他们就会遇到这样的情况。想象一下:你正在编写代码,试图插入和处理第二个键落入第一个单元的情况,然后发生了碰撞。我们需要弄清楚下一步该怎么做。 首先,我们必须循环查看单元格,判断每个单元格是否为空,是否可以写入,或者是否已被删除。假设内存已经初始化,我们需要能够区分单元格是空的(即未赋值或删除后为空)还是仅仅包含一个空值,比如在ClickHouse中,我们支持可空类型。  在这种情况下有几种选择。第一种方案是要求哈希表用户提供一表示空单元格的默认键,以及表示已删除单元格的墓碑键。这些值永远不会被用户插入到哈希表中。也就是说,它不在真实数据中,因此我们可以用它来识别单元格为空或已删除。 Google的Flat Hash Map中就使用了这种方法。这种方法的主要缺点是,我们必须让客户端选择一些不会出现在其数据中的键。有时很容易找到这种键,有时却很难.但总的来说,这会使API复杂化。从图中可以大致看出这一点:哈希表中有一些插槽,其中有些是空键,有些是墓碑。这样,我们就可以安全地检查这个槽是否为空。  我们ClickHouse使用的是一种更先进的方法,如上图所示。我们不在哈希表中保留空单元格。我们为Null元素设置了一些特殊单元格,并将其单独保存[^nullmap]。在插入或查找哈希表之前,我们首先检查值是否为Null,然后单独进行处理。这样做的缺点是**执行流会出现一个额外的分支,但实际上CPU中的分支预测器能非常有效地隐藏额外的成本**,因此我们的性能不会受到影响。 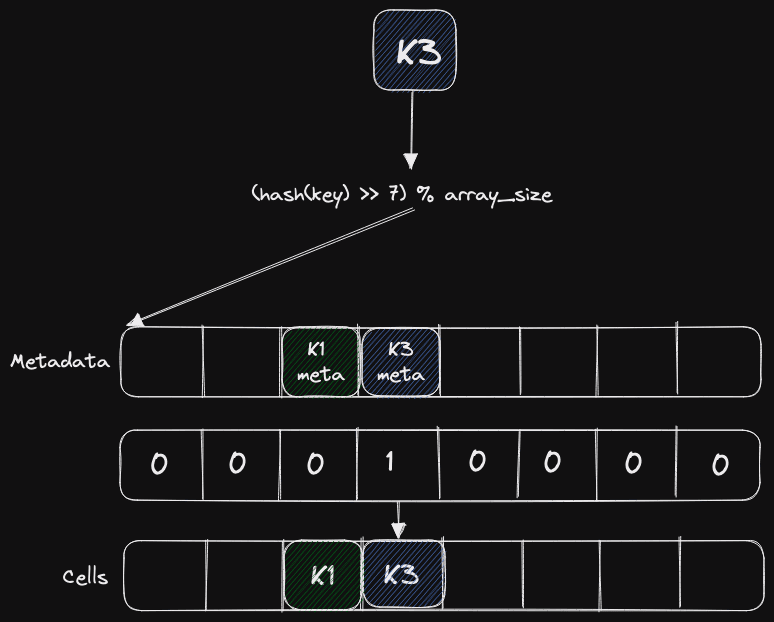 还有一种相当复杂的方法,谷歌最新推出的哈希表中就使用了这种方法。要使用这种方法,需要从较简单的情况入手。例如,我们想在某个地方保存单元格是否被删除或为空的信息。如果将其写入哈希表,就会浪费更多内存。因此,我们会将其保存在其他地方,例如元数据中。 但是,由于我们只需要两个比特,因此将其用于记录这些信息的成本很高。我们当然可以用一整个字节,但其余的比特呢?在谷歌的实现中,哈希值的高53位用来查找单元格及其元数据,而其余比特则存在元数据中。 为什么这会有用?我们可以将这些数据存放在寄存器中,然后快速判断是否需要查看相关的单元,例如——使用SSE指令。 ## 基准测试 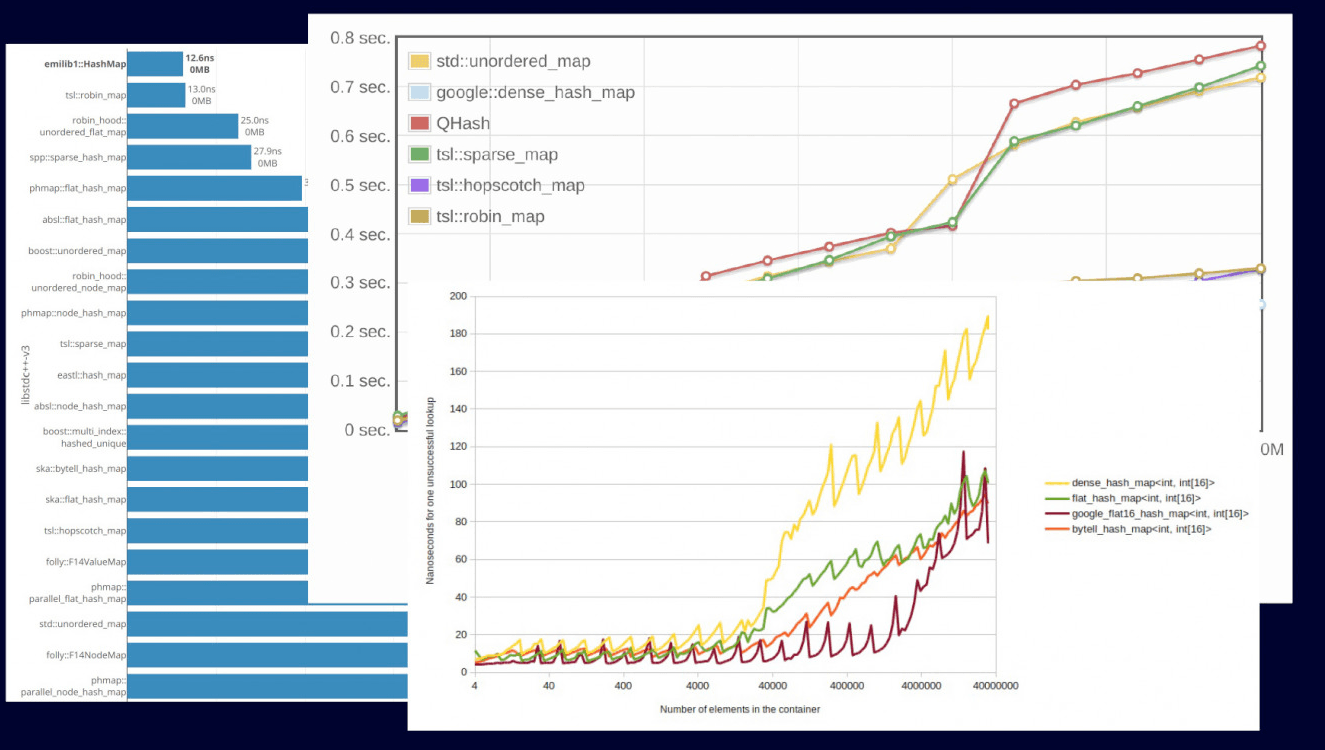 如果你去查哪个哈希表是最好的,那么互联网上每两个人都会写出自己心目中不同的最快哈希表。如果你开始深入研究,就会发现事实并非如此。许多基准测试并没有涵盖重要的内容,也没有使用任何特定的场景。因此,哈希表的速度到底快不快并不是个鲜明的事实。 基准测试的主要问题是什么?它们通常不是基于真实数据,而是基于随机数。**随机数的分布与真实数据并不一致**。此外,基准测试往往不考虑具体情况。同样常见的是,它们不显示基准代码,只显示各种图表,导致无法重复这些测试。 应该如何进行基准测试?它们需要在真实数据和真实场景中进行。在ClickHouse中,真实场景是数据聚合,我们从[web analytics dataset](https://clickhouse.com/docs/en/getting-started/example-datasets/metrica)中获取数据本身,你可以从我们的网站上下载。 现在,让我们来看看这些基准,并尝试分析不同的设计决策会如何影响哈希表的性能。 以下结果基于包含约`2,071,4865`个Unique值的 `WatchId`列。这些值无法全部放入CPU cache中——它们占用了约600MB的空间,因此必须产生内存访问。此处的时间代表聚合所有值的总运行时间。 | Hashtable | Time (seconds) | | ------------------- | -------------- | | ClickHouse HashMap | 7,366 secs | | Google DenseMap | 10,089 secs | | Abseil HashMap | 9,011 secs | | std::unordered\_map | 44,758 secs | 如果我们看一下这个基准,就会发现ClickHouse的哈希表远远领先于 `std::unordered_map`。为什么呢?因为,正如我所说的,`std::unordered_map`并非本地缓存。具体来说,这些数据并没有放在CPU的L-cache中。我们可以用 `perf stat`来查看,以证实我们的猜想:`std::unordered_map`有更多的缓存未命中,从而导致了速度劣势。 | Hashtable | Cache misses | | ------------------- | ------------- | | ClickHouse HashMap | 329,644,616 | | Google DenseMap | 383,350,820 | | Abseil HashMap | 415,869,669 | | std::unordered\_map | 1,939,811,017 |  我们还可以查看一些数字,以确认访问主存与访问L1或L2高速缓存相比成本更高。我们可以断言,**为了让哈希表以最快速度运行,必须对缓存位置进行优化**。 我们再来看一个稍有不同的基准,在这个基准中,所有数据都进入了缓存。在这种情况下,我们会发现 `std::unordered_map`的运行速度不再那么慢了。在这种情况下,我们使用一个 `RegionID`列,该列的重复值产生自一组 `9040`个唯一值,这些唯一值都可以放入CPU cache。 | Hashtable | Time (secs) | | ------------------- | ----------- | | ClickHouse HashMap | 0.201s | | Google DenseMap | 0.261s | | Abseil HashMap | 0.307s | | std::unordered\_map | 0.466s | # C++哈希表设计 到目前为止,我们主要关注的部分还是算法得设计。但是,为了使所有这些算法都能很好地运行在实际工程中,我们需要开发一套灵活而强大的C++封装。 我们的哈希表封装器采用了策略模式,即每个设计选择都是哈希表接口的独立部分。主要接口包括哈希函数、分配器、单元(散列表中的重要元素)、增长器(调整大小策略的接口),以及将所有这些组件组合在一起的哈希表本身。 让我们从哈希函数开始。它与C++11中引入的 `std::hash`接口相同,没什么特别的: ```cpp template <typename T> struct Hash { size_t operator () (T key) const { return DefaultHash<T>(key); } }; ``` 而分配器相比于C++标准库的接口就略有改动了——因为我们的版本支持 `realloc`。为什么需要 `realloc`?因为在Linux中,我们使用 `mmap`和 `mremap`来处理大型哈希表。为了支持这一点,我们需要在接口中提供一个 `realloc`方法。 下面的分配器使用 `mmap`和 `mremap`来分配大内存块: ```cpp class Allocator { void * alloc(size_t size, size_t alignment); void free(void * buf, size_t size); void * realloc(void * buf, size t old size, size_t new size); }; ``` 如果使用对应的自定义策略,我们还有一个一开始就在栈上分配内存的分配器: ```cpp AllocatorWithStackMemory<HashTableAllocator, initialbytes> ``` 哈希表单元(hash table cell)代表哈希表的一个正式元素;你可以向它写入哈希值,从中获取哈希值,并检查它是否为空。此外,单元格本身也能提供整个哈希表的一些信息,也就是说,由于单元格是由表状态参数化的,因此它能理解哈希表中的内容[^cell-state]。 ```cpp template <typename Key, typename Mapped, typename HashTableState> struct HashTableCell { ... void setHash(size_t hash_value); size_t getHash(const Hash & hash) const; bool isZero(const State & state); void setZero(); ... }; ``` 以下是我们调整大小策略的接口,其中的函数用于在哈希表中获取位置、移动到下一个元素、检查插入下一个元素是否会导致表溢出,以及调整自身大小。让我们直接用代码定义它们。 ```cpp struct HashTableGrower size_t place(size_t x) const; size_t next(size_t pos) const; bool willNextElementOverflow() const; void increaseSize(); }; ``` 哈希表是由 C++ 模板生成的,该模板通过继承所有这些接口来组合它们。与在运行时使用虚函数进行组合不同,[这种方法](https://github.com/ClickHouse/ClickHouse/blob/23.4/src/Common/HashTable/HashTable.h#L444)能确保最佳性能,因为编译器能对生成的每个哈希表进行单独优化[^crtp]。 ```cpp template < typename Key, typename Cell, typename Hash, typename Grower, typename Allocator > class HashTable : protected Hash, protected Allocator, protected Cell::State; protected ZeroValueStorage<Cell::need_zero_value_storage, Cell> ``` 举个例子,我们如何处理零值存储?如果其中一个基类不包含数据,我们就不会浪费额外的内存来存储它。例如,我们在上文提到,ClickHouse会单独生成零值单元格,并将其放置在一个特殊的零值存储器中。但只有在某些情况下才需要这样做。假设我们不需要它,在这种情况下,零值存储就是一种不做任何事情的特殊化,编译器会删除不必要的代码,而且不会降低速度。 ```cpp template ‹bool need_zero_value_storage, typename Cell> struct ZeroValueStorage; template <typename Cell> struct ZeroValueStorage<true, Cell> { ... }; template <typename Cell> struct ZeroValueStorage<false, Cell> { ... }; ``` 自定义扩缩容策略能给我们带来什么?一个定长的、不考虑哈希冲突的自定义扩缩容策略,其生成的哈希表完全适合缓存最近的元素。使用因子不等于1的扩缩容策略,我们可以轻松实现二次探查等功能,这对于检查各种基准非常方便。 在单元格中附带状态的功能可以帮助我们**在单元格中存储有用的信息,例如哈希值**。这样,我们就不需要重复计算哈希函数了。 ```cpp struct HashMapCellWithSavedHash : public HashMapCell { size_t saved_hash; void setHash(size_t hash_value) { saved_hash = hash_value; } size_t getHash(const Hash &) const { return saved_hash; } }; ``` 我们还可以制作一个可以快速清空的哈希表。当我们有一个庞大的哈希表,并且已经在其中填满了数据,现在想复用它时,这种方法就非常有用。要删除哈希表中的所有元素,我们使用哈希表的版本作为状态——我们将版本存储在单元格和哈希表本身中。在检查单元格是否为空时,我们只需比较单元格和哈希表的版本。如果**需要快速删除,我们会将哈希表的版本递增一个。这比试图删除哈希表中的所有单元格更有效**,因为删除单元格会要求我们对哈希表进行遍历,从而导致大量的缓存缺失,造成糟糕的性能表现。 ```cpp struct FixedClearableHashMapCell { struct ClearableHashSetState { UInt32 version = 1; }; using State = ClearableHashSetState; UInt32 version = 1; bool isZero(const State & st) const { return version ! = st.version; } void setZero() { version = 0; } } ``` 另一个有趣的技巧是LRU缓存。这是[LRU排除策略](https://www.educative.io/implement-least-recently-used-cache)的一种实现方式。通常,它是以双链LRU列表和哈希表的形式实现的,哈希表提供了从键到列表中位置的快速映射。每次引用特定键时,我们都需要将值移动到列表的“最新”一端,并更新哈希表中值的映射。如果某个元素尚未存储在LRU缓存中,我们就会删除列表“最近”一端的元素,并插入新的元素。当列表已满时,我们会从列表开头移除该元素。这样,列表中就会始终包含最新的一些元素。 使用单独的列表和哈希表来实现LRU缓存并不是最佳方案,因为它使用了两个容器。而在ClickHouse中,我们找到了在单个容器中实现这一功能的方法。在哈希表**单元中,我们存储了一个指向下一个和上一个元素的指针,从而在哈希表中形成了一个双链表**。 ```cpp struct LRUHashMapCell { static bool constexpr need_to_notify_cell_during_move = true; static void move(LRUHashMapCell * old_loc, LRUHashMapCell * new_loc); LRUHashMapCell * next = nullptr; LRUHashMapCell * prev = nullptr; }; ``` 为了实现这一点,我们存储了两个指针,并使用了Boost Instrusive库[^instrusive]。下面我们将展示其中最重要的部分。我们创建一个侵入式列表,并将其作为列表使用。我们声明了指向单元格中下一个和上一个元素的指针,这足以让我们在单元格顶部创建一个侵入式列表。 ```cpp using LRUList = boost:: intrusive:: list < Cell, boost::intrusive::value_traits<LRUHashMapCellIntrusiveValueTraits>, boost::intrusive::constant_time_size<false> >; LRUList ru_list ; ``` 我们有几种专门的哈希表,适用于各种情况。例如,`SmallTable`是一个实现成数组的哈希表。它有什么用呢?——它被放在L1缓存中,并实现了哈希表接口。如果我们需要实现一种简单的算法,这就非常有用。 ```cpp template <typename Key, typename Cell, size_t capacity> class SmallTable : protected Cell:: State { size_t m_size = 0; Cell buf[capacity]; ... } ``` 我们还有一个更有趣的哈希表——[字符串哈希表](https://www.mdpi.com/2076-3417/10/6/1915)。它是由一位来自中国的研究生贡献给我们的。这是四个不同长度字符串的哈希表,我们使用了不同的哈希函数。更具体地说,这个哈希表由4个哈希表组成: * 长度为 0-8 字节的字符串 * 长度为 9-16 字节的字符串 * 长度为 17-24 字节的字符串 * 长度大于 24 字节的字符串 另一个非常有趣的哈希表是两级哈希表。它由256个哈希表组成。排除你是个哈希狂热粉的因素,有什么理由搞这么多呢?举例来说,当我们进行 `GROUP BY`操作时,我们希望在多个线程中进行操作。因此,我们需要填充表,然后合并它们。我们**可以使用无锁哈希表,但团队中没人喜欢无锁哈希表,所以我们使用两级哈希表**。 这可以通过在每个线程中创建两级哈希表来实现。例如,如果我们有四个流,就会得到一个包含256列(表)和四行(流)的矩阵。我们将数据插入其中一个表中。例如,我们按照下图所示的公式进行分配。然后,当我们需要 `JOIN`表时,我们使用最少的同步开销并按列 `JOIN`它们。最终,一切都不会慢下来。 ```cpp size_t getBucketFromHash(size_t hash_value) { return (hash_value >> (32 - BITS_FOR_BUCKET)) & MAX_BUCKET; } ``` 因此,我们自己编写了一个相当灵活且功能强大的框架来实现哈希表。你可以从中获得适用于不同场景的哈希表。 我想承认:我真的很喜欢哈希表。对于那些能够改进我们的基准的人,例如,制作出比我们的哈希表更快的哈希表,我们将提供一件独一无二的“ClickHouse does not slow down连帽衫”! [^instrusive]: 译者注:侵入式指针,可以减少内存申请次数以提高性能。 [^crtp]: 译者注:即CRTP。 [^cell-state]: 译者注:即HashTableState。 [^nullmap]: 译者注:即单独的Null Map方法? [^resize]: 译者注:因为需要计算哈希函数后总需要对表大小取模。 [^libdivide]: 译者注:[https://libdivide.com/](https://libdivide.com/) [^two-way]: 译者注:类似布谷哈希,但使用两个哈希表。 [^cuckoo]: 译者注:在冲突时采用另一个哈希函数计算地址。 [^open]: 译者注:采用开放寻址法,在查找时也需要按相同的规则逐个单元格查找,直到为空才能宣布失配。 © 允许规范转载 打赏 赞赏作者 赞 9 如果觉得我的文章对你有用,请随意赞赏