Loading... # perf perf是最常用的C++性能工具. 它能够产生调用图及svg格式的火焰图, 非常human-friendly. 它的原理是以固定的频率产生中断, 然后窥探函数调用栈的状态. 如果连续多次都发现调用栈状态相同, 那么就可以假设在这一段时间内该函数在持续执行. ## 使用方法 ```powershell perf record -F 99 -g -p <pid> [--call-graph (fp|dwarf|lbr)] [-e <event...>] ``` 其中`-F`指定了每秒产生中断的次数, 一般我们设置为99次. `-g`指示产生函数调用关系, 这是火焰图必不可少的一部分. `-p`则指定观察的进程pid. `--call-graph`指定对调用链进行采样的方式, 其中`lbr`为**一般意义下最佳**. 接下来, 我们可以通过 ```powershell perf report ``` 进入**交互式界面**, 非常便捷的深入观察各个函数之间时间开销, 热点和调用关系: 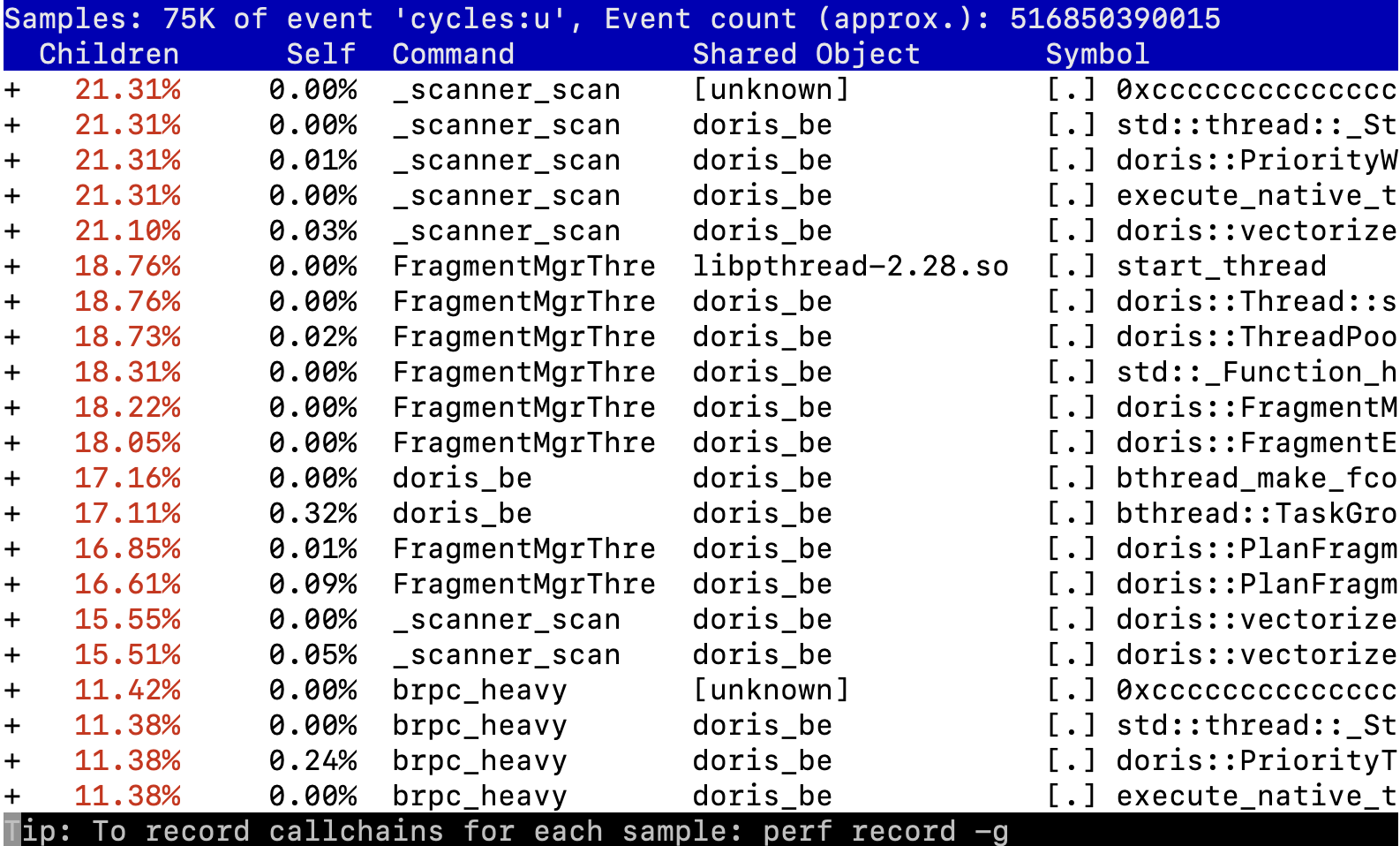 这个界面的功能非常强大,我们可以跳转到对应的函数内部查看其汇编代码。不过此时显示的一般是时钟周期的统计视角,如果我们需要统计其他的内容,可以通过`-e event`**指定perf统计的事件**,之后使用`perf report`时也就可以查看这些事件视角的分析了。 ## 火焰图 使用perf进行性能分析,很重要的一个环节就是生成火焰图。首先需要我们下载FlameGraph这个工具: ```powershell git clone https://github.com/brendangregg/FlameGraph cd FlameGraph ``` 下载好FlameGraph之后, 通过下列命令生成火焰图: ```powershell perf script | ./stackcollapse-perf.pl > out.perf-folded ./flamegraph.pl out.perf-folded > perf.svg ``` 然后我们就可以使用浏览器观察该火焰图了, 由于是svg格式的, 所以我们可以任意跳转到细节部分进行观察. 例如: 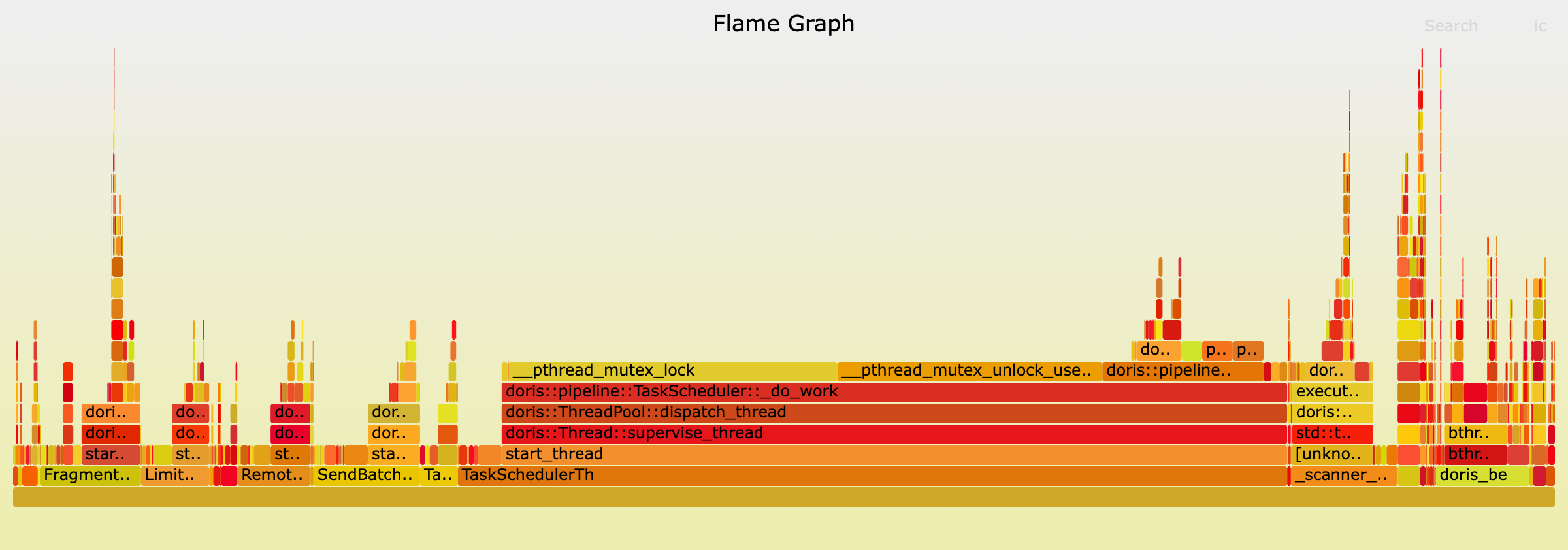 ## perf stat `perf record`是对进程进行详细的记录,而 ```powershell perf stat -B -e <events>[,...] -p <pid> ``` 可以针对特定进程**记录特定的事件**列表, 例如分支预测命中率, 缓存命中率等等,产生效果如下: 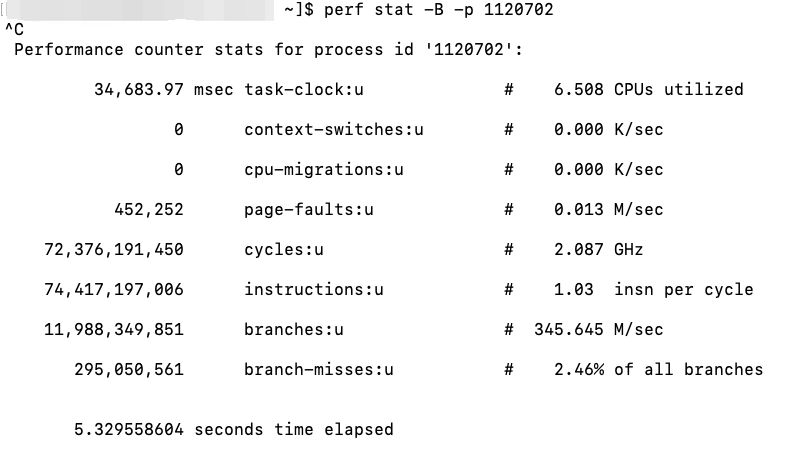 这也是一个非常重要的功能,因为很多时候,代码在算法层面已经达到最优了,而由于对于循环、变量的使用未能达到最优,所以导致了比较明显的性能问题。这部分问题,就要通过对于page-fault、cache-miss的分析得出结论了。 ## 常用功能 ```powershell perf list // 列出各种事件, 比较常见的有: branches,branch-load-misses,cache-misses,cycles,instructions,dTLB-load-misses,L1-dcache-load-misses perf annotate --symbol=xxx // 查看特定符号(一般是函数)耗时,在perf record中也可以直接查看。 ``` 我们在新的文章中, 会使用一个具体的性能优化例子,详细介绍perf的具体应用流程. # valgrind valgrind作为内存泄漏检测工具而被人所熟知, 事实上这只是它的其中一个功能. 它还包含了例如callgrind(检查调用性能), cachegrind(检查缓存命中率)等工具. ## Callgrind callgrind是著名工具valgrind的一个组件,可以生成函数调用关系及用时。基本用法在[官方manual](https://valgrind.org/docs/manual/cl-manual.html#cl-manual.basics)很完整。 首先我们通过valgrind运行对应程序: ```powershell valgrind --tool=callgrind [callgrind options] your-program [program options] ``` 然后会生成对应的`callgrind.out.<pid>`文件,我们需要用另一个工具(也在valgrind内)输出function-by-function的报告: ```powershell callgrind_annotate --inclusive=yes --tree=both callgrind.out.<pid> ``` 包含了两个推荐的选项。 然后就可以看到human-friendly的统计内容(可以重定向到文件中): 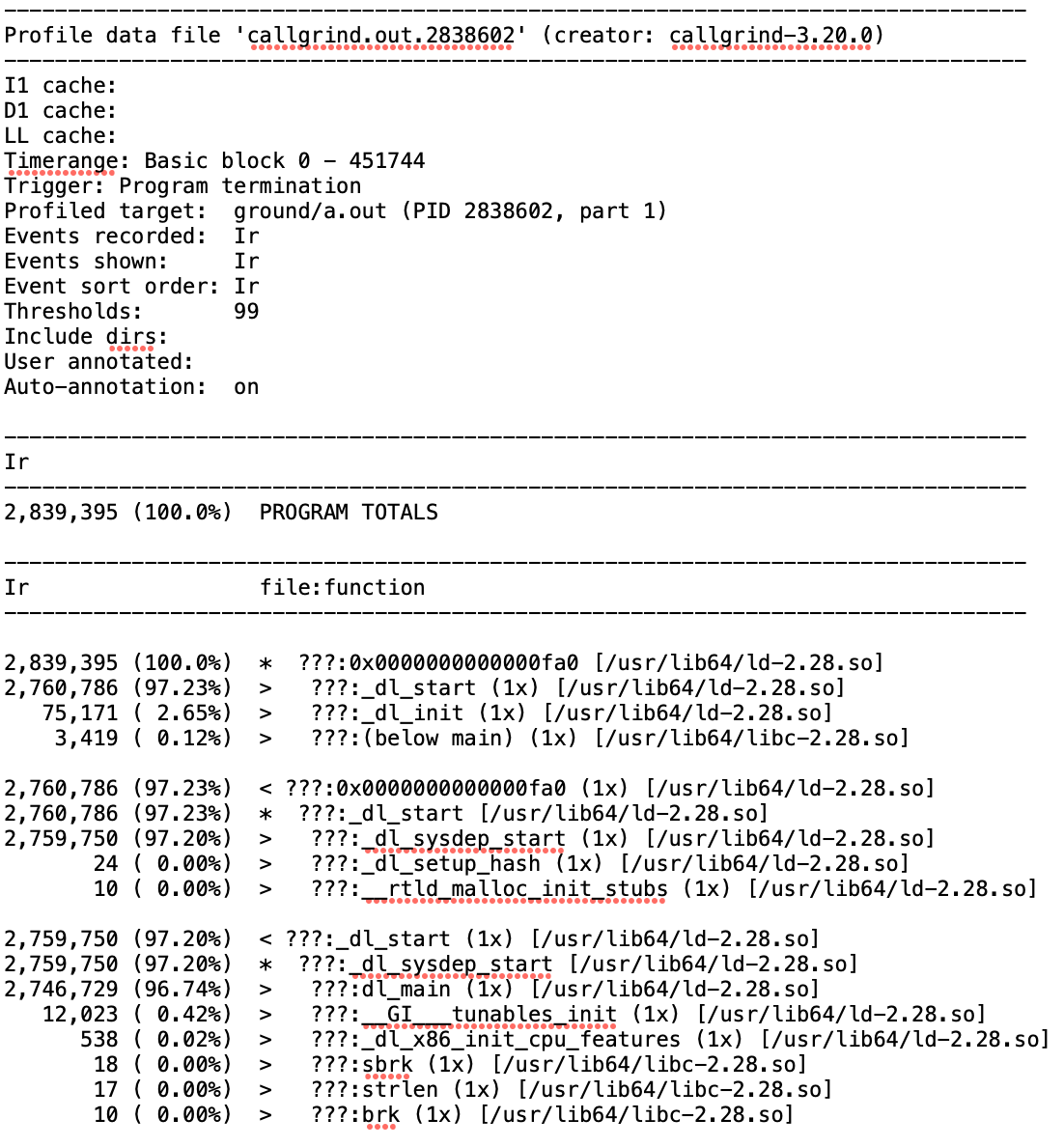 但这样的文件仍然不好阅读,实际上valgrind也有对应的GUI去分析这个文件——[**kcachegrind**](hhttps://kcachegrind.sourceforge.net/html/Documentation.html)。 在Mac上,对应的工具是QCachegrind,可以直接通过`brew`下载,同时应该附带下载`graphviz`,这样就可以直接分析`callgrind.out.<pid>`文件了: 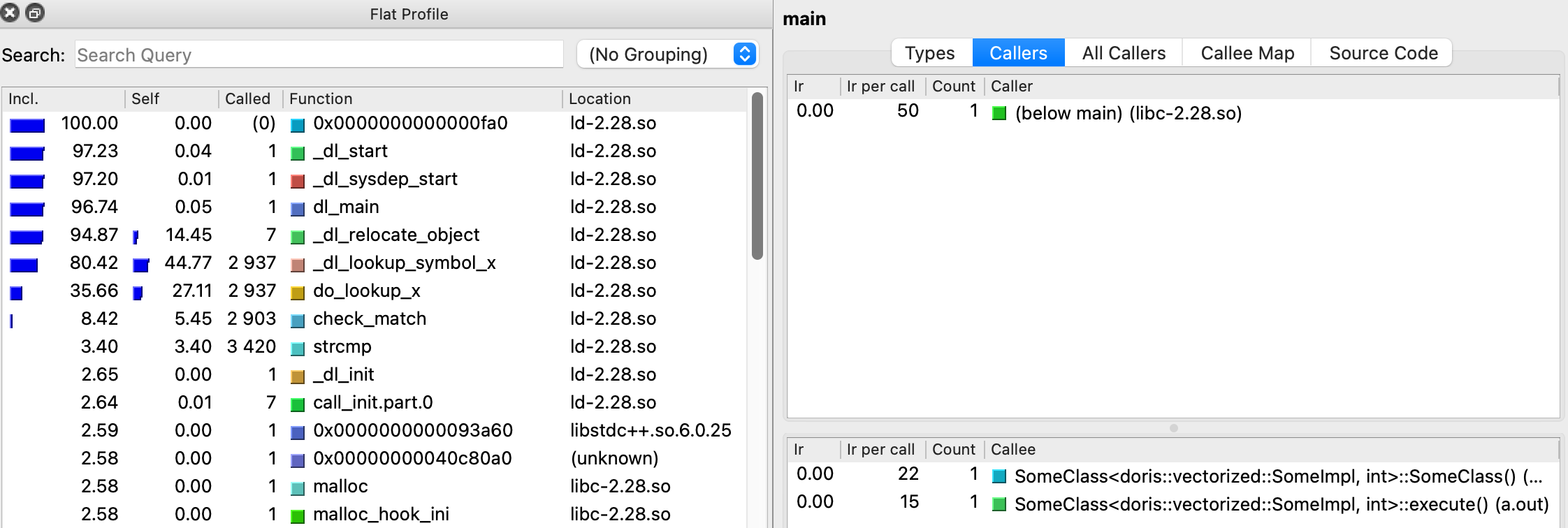 # Quick Benchmark 如果我们对于一个场景提出了多个解决方案, 或者说想出了一种可能的性能优化手段, 但不清楚到底什么样效率是最优的, 那么[Quick Benchmark](https://quick-bench.com/)就是我们所需要的了. 提出一个最小实现, 然后用它可以快速的测量代码之间的性能差距. 例如: ```cpp constexpr int N = 100000; static void A(benchmark::State& state) { for (auto _ : state) { std::vector<int> arr; for (int i = 0; i < N; i++) arr.emplace_back(123); benchmark::DoNotOptimize(arr); } } BENCHMARK(A); static void B(benchmark::State& state) { for (auto _ : state) { std::vector<int> arr; arr.reserve(N); for (int i = 0; i < N; i++) arr.emplace_back(123); benchmark::DoNotOptimize(arr); } } BENCHMARK(B); static void C(benchmark::State& state) { for (auto _ : state) { std::vector<int> arr(N); for (int i = 0; i < N; i++) arr[i] = 123; benchmark::DoNotOptimize(arr); } } BENCHMARK(C); ``` 结果: 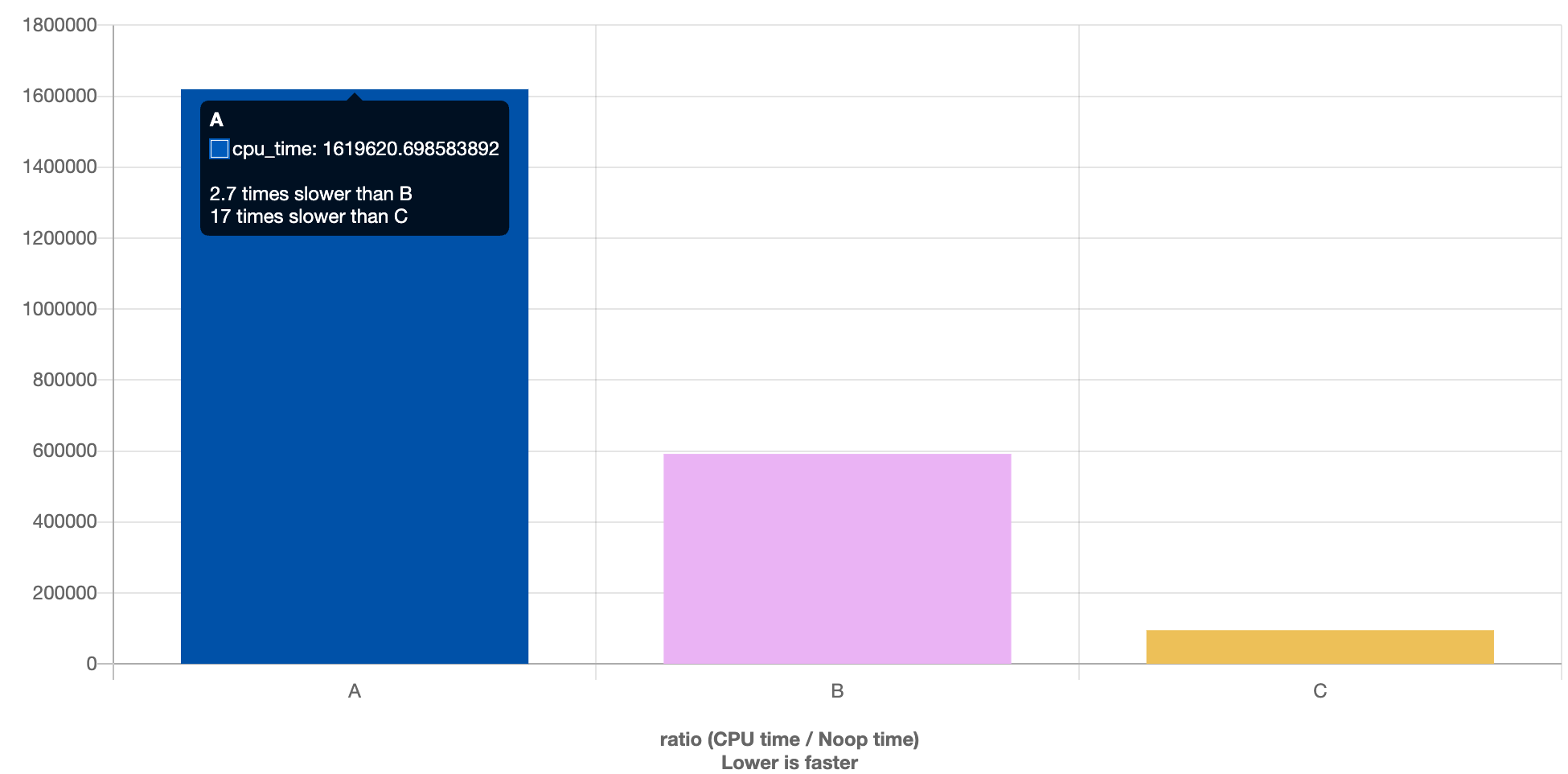 注意调试不同编译器&优化等级的影响. <div class="tip inlineBlock error"> 在进行优化前使用Benchmark确认有效非常重要, 避免做无用功! </div> © 允许规范转载 打赏 赞赏作者 赞 4 如果觉得我的文章对你有用,请随意赞赏